Mistral Small 3.1 已经正式发布!完全免费开源,具有更先进的文本性能、多模式理解和高达 128k 个标记的扩展上下文窗口。该模型的表现优于 Gemma 3 和 GPT-4o Mini 等同类模型,同时提供每秒 150 个标记的推理速度。
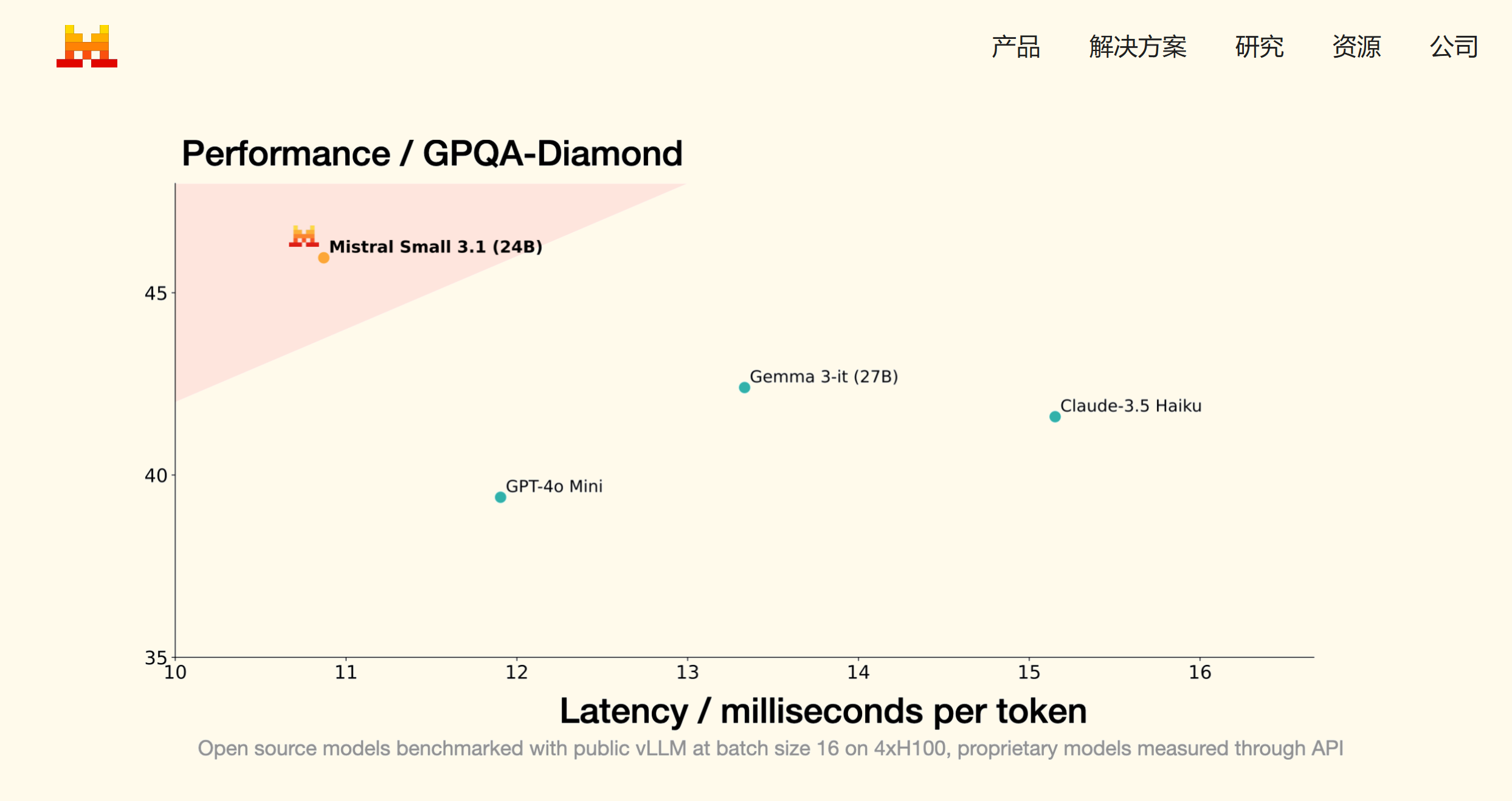
现代 AI 应用程序需要多种功能(处理文本、理解多模式输入、支持多种语言以及管理长上下文),同时还要具有低延迟和成本效益。如下所示,Mistral Small 3.1 是第一个不仅满足而且实际上超越了领先的小型专有模型在所有这些维度上的性能的开源模型。
下面您将找到有关模型性能的更多详细信息。只要有可能,我们就会显示其他提供商之前报告的数字,否则我们会通过我们的通用评估工具来评估模型。
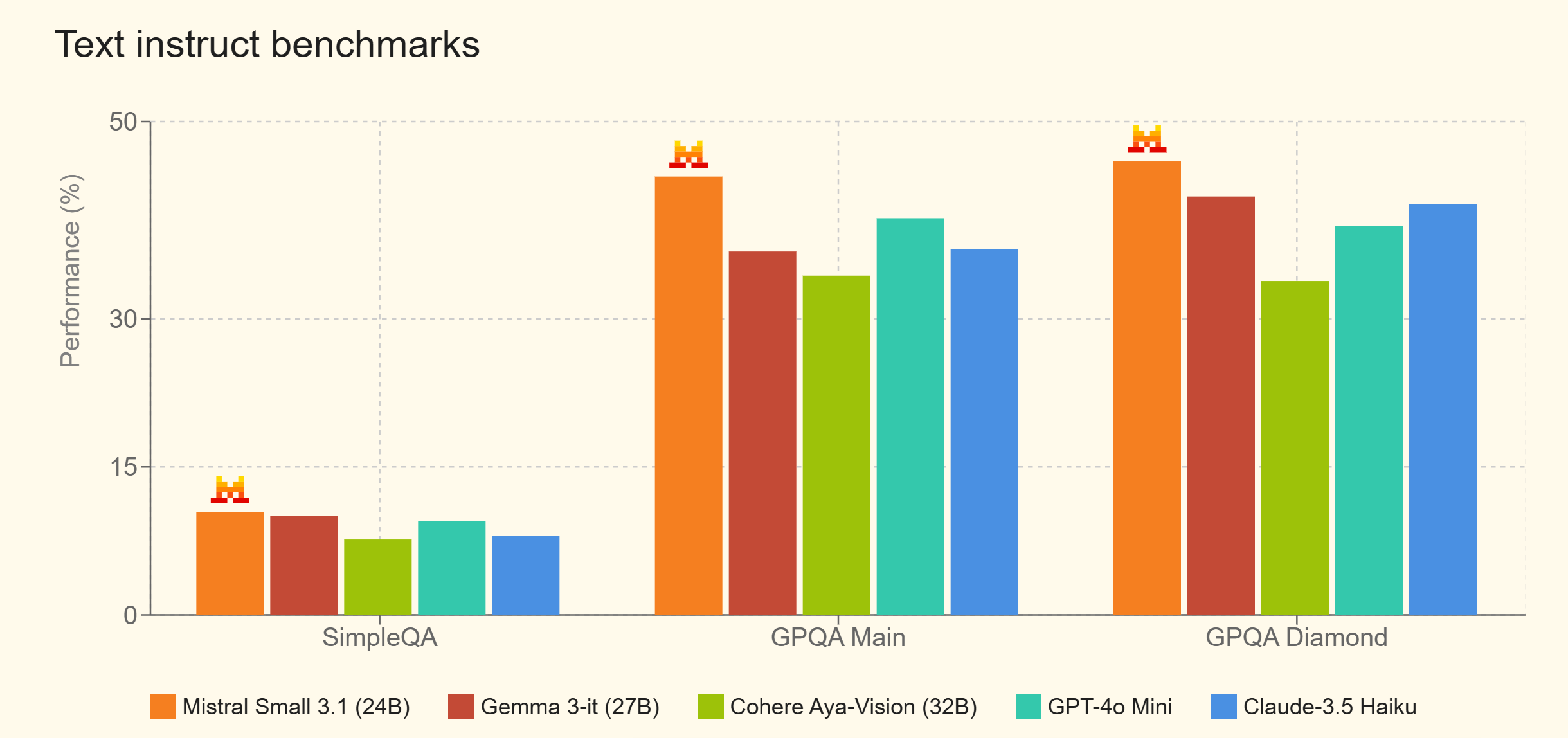
文本基准评分
Mistral Small 3.1 可用于需要多模式理解的各种企业和消费者应用程序,例如文档验证、诊断、设备上图像处理、质量检查的视觉检查、安全系统中的物体检测、基于图像的客户支持和通用协助。
本地部署教程:
1、通过Ollama客户端快速部署 【点击下载】
2、一键部署命令:
24B模型
ollama run MHKetbi/Mistral-Small3.1-24B-Instruct-2503量化版,适合小显存的显卡
【点击前往】
3、WebUI 调用本地 Mistral Small 3.1 AI模型 【点击安装】,方便大家使用,支持Chrome、Edge等浏览器。
主要特性和功能
-
轻量级:Mistral Small 3.1 可以在单个 RTX 4090 或具有 32GB RAM 的 Mac 上运行。这使其非常适合设备上的使用情况。
-
快速响应对话帮助:非常适合虚拟助手和其他需要快速、准确响应的应用程序。
-
低延迟函数调用:能够在自动化或代理工作流程中快速执行函数
-
针对专业领域进行微调:Mistral Small 3.1 可以针对特定领域进行微调,打造精准的主题专家。这在法律咨询、医疗诊断和技术支持等领域尤其有用。
-
高级推理的基础:社区在开放的 Mistral 模型之上构建模型的方式继续给我们留下深刻印象。仅在过去几周,我们就看到了几个基于 Mistral Small 3 构建的出色推理模型,例如Nous Research 的DeepHermes 24B。为此,我们发布了 Mistral Small 3.1 的基础和指令检查点,以便进一步对模型进行下游定制。
没有GPU的用户也不用担心,你完全可以在Mistral 官方平台上使用,上面也是满血版【点击前往】