

Gemma 3 被谷歌称为目前最强的开源视觉模型之一。 该模型支持超过35种语言,能够分析文本、图像和短视频。值得注意的是,Gemma 3 的视觉编码器经过升级,支持高分辨率和非方形图像,并引入了 ShieldGemma 2 图像安全分类器,用于过滤被分类为性暗示、危险或暴力的内容。这些特性使得 Gemma 3 成为当前最强大的开源视觉模型之一。
![图片[1]-谷歌 Gemma 3 发布:更强大、更智能的多模态 AI,本地轻松部署使用!-零度博客](https://www.freedidi.com/wp-content/uploads/2025/03/b6e32a147120250315105941.webp)
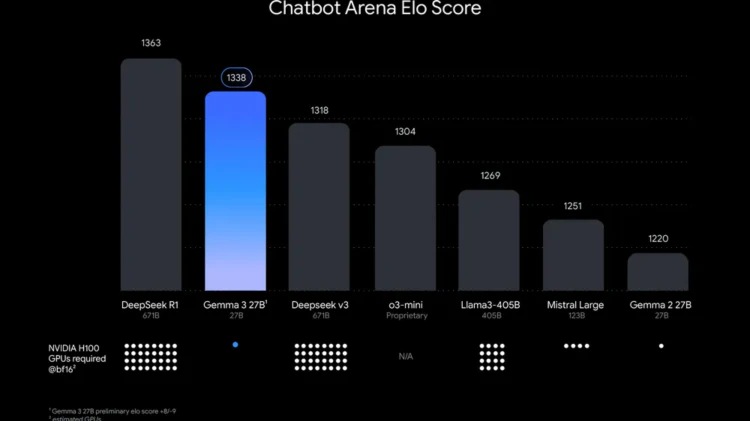
此图表按 Chatbot Arena Elo 得分对 AI 模型进行排名;得分越高(数字越大),表示用户偏好越高。点表示估计的 NVIDIA H100 GPU 要求。Gemma 3 27B 排名靠前,只需要一个 GPU,而其他模型则需要多达 32 个。
最新的 Gemma 3 多模态开源模型新功能
- 使用世界上最好的单加速器模型进行构建: Gemma 3 以其尺寸提供最先进的性能,在 LMArena 排行榜的初步人类偏好评估中胜过 Llama3-405B、DeepSeek-V3 和 o3-mini。这可以帮助您创建可安装在单个 GPU 或 TPU 主机上的引人入胜的用户体验。
- 以 140 种语言走向全球:构建使用客户语言的应用程序。Gemma 3 提供对超过 35 种语言的开箱即用支持和对超过 140 种语言的预训练支持。
- 打造具备高级文本和视觉推理能力的AI:轻松构建分析图片、文本、短视频等应用,开启交互智能化新可能1。
- 使用扩展的上下文窗口处理复杂任务: Gemma 3 提供 128k 令牌上下文窗口,让您的应用程序处理和理解大量信息。
- 使用函数调用创建 AI 驱动的工作流程: Gemma 3 支持函数调用和结构化输出,以帮助您自动执行任务并构建代理体验。
- 通过量化模型更快地实现高性能: Gemma 3 引入了官方量化版本,减少了模型大小和计算要求,同时保持了高精度。
本地安装,单显卡可以选择1b,4b,12b,27b,推荐选择27b,因为Gemma 3 27B 处于帕累托最佳点
![图片[2]-谷歌 Gemma 3 发布:更强大、更智能的多模态 AI,本地轻松部署使用!-零度博客](https://www.freedidi.com/wp-content/uploads/2025/03/01f57e029220250315110307.webp)
| 预先训练 | 指令调整 | 多式联运 | 多种语言 | 输入上下文窗口 |
|---|---|---|---|---|
| gemma-3-1b-pt | gemma-3-1b-it | ❌ | 英语 | 32千 |
| Gemma-3-4b-pt | gemma-3-4b-it | ✅ | +140 种语言 | 128千 |
| gemma-3-12b-pt | gemma-3-12b-it | ✅ | +140 种语言 | 128千 |
| gemma-3-27b-pt | gemma-3-27b-it | ✅ | +140 种语言 | 128千 |
对于 1B 版本,输入上下文窗口长度已从 Gemma 2 的 8k 增加到32k ,对于其他所有版本,则增加到 128k。与其他 VLM(视觉语言模型)一样,Gemma 3 会根据用户输入生成文本,这些文本可能由文本组成,也可能由图像组成。示例用途包括问答、分析图像内容、总结文档等。
本地部署Gemma 3开源大模型:
1、下载官方 Ollama 【点击前往】 ,并通过下方的安装命令执行下载:
普通用户建议选择4b和12b,显卡好的可以上27b
ollama run gemma3:1b
ollama run gemma3:4b
ollama run gemma3:12b
ollama run gemma3:27b2、通过Chrome插件调用本地Gemma 3视觉大模型【点击下载】
![图片[3]-谷歌 Gemma 3 发布:更强大、更智能的多模态 AI,本地轻松部署使用!-零度博客](https://www.freedidi.com/wp-content/uploads/2025/03/fd7519f83320250315110759-scaled.webp)
就可以愉快的使用了
![图片[4]-谷歌 Gemma 3 发布:更强大、更智能的多模态 AI,本地轻松部署使用!-零度博客](https://www.freedidi.com/wp-content/uploads/2025/03/6496a0c00620250315110956.webp) 可以很好的对图片进行识别:
可以很好的对图片进行识别:
![图片[5]-谷歌 Gemma 3 发布:更强大、更智能的多模态 AI,本地轻松部署使用!-零度博客](https://www.freedidi.com/wp-content/uploads/2025/03/f6d7dd8f2b20250315111219.webp)
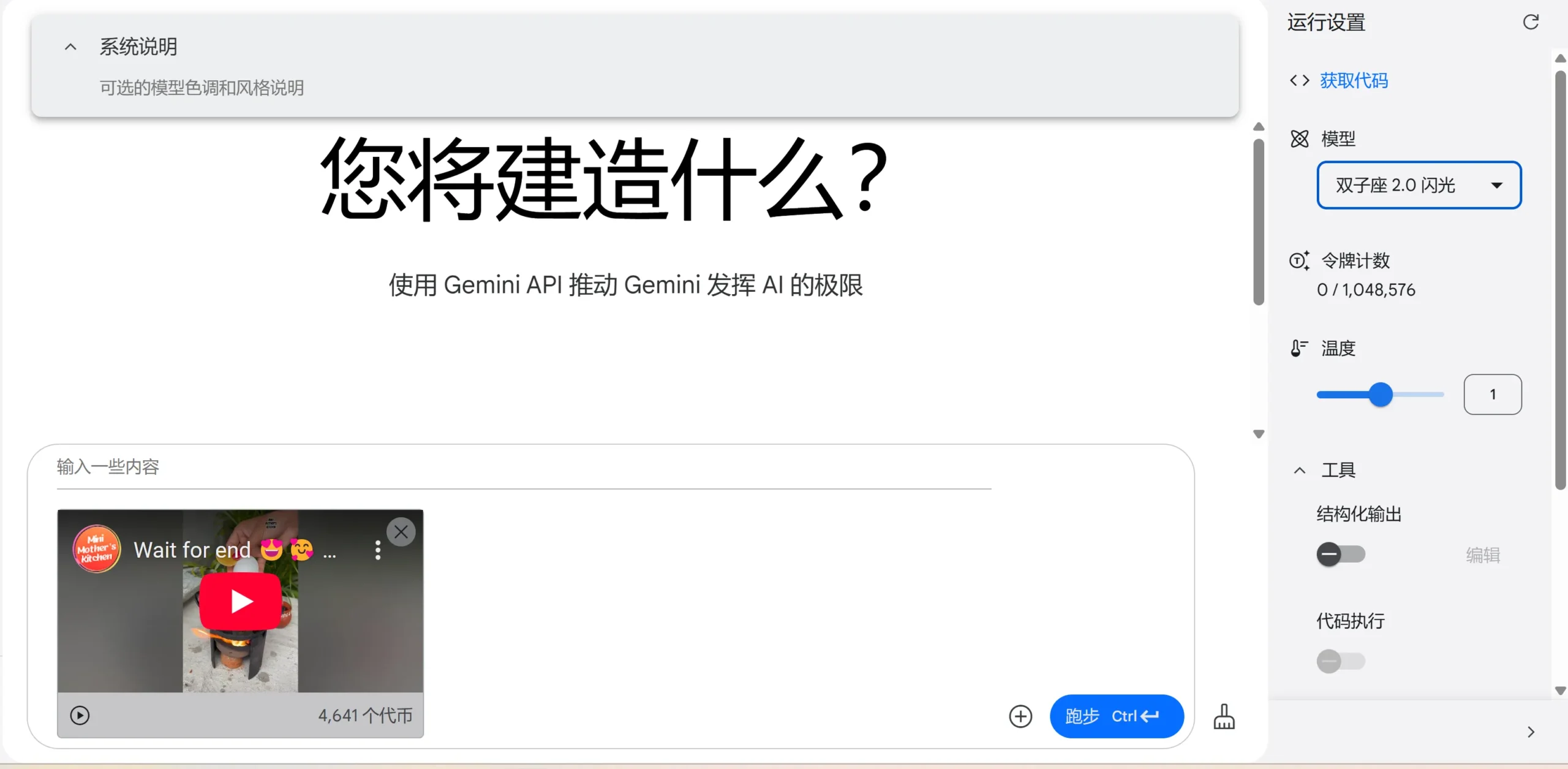
当然你可以使用Google AI Studio 对短视频进行分析,支持上传和链接
Google AI Studio :【点击前往】
THE END






![HARDiNFO 8 Professional – 免费获取专业系统信息查看工具 [Windows][$39.5→免费]-零度博客](https://www.freedidi.com/wp-content/uploads/2025/01/89266be3ba20250107125111.webp)