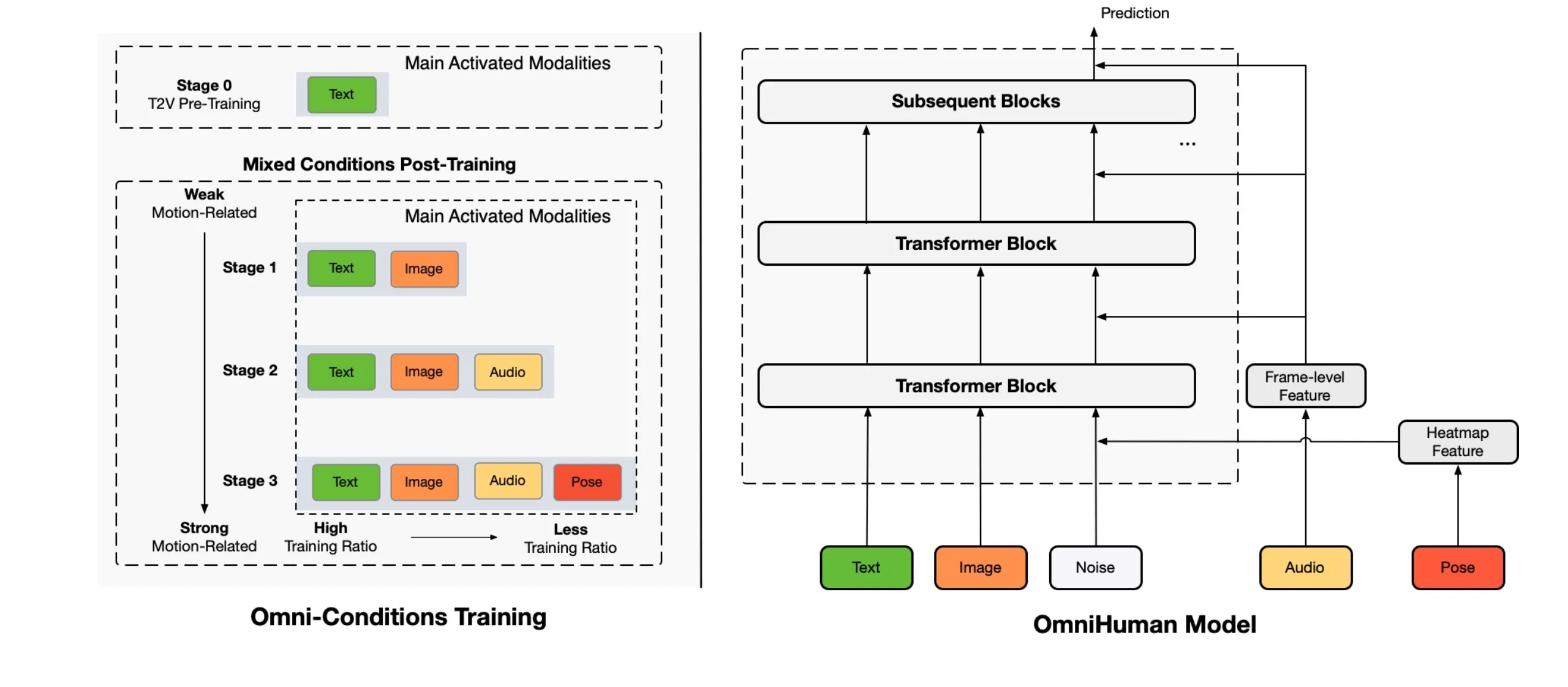
OmniHuman 支持多种视觉和音频风格,可生成任意长宽比和身体比例(人像、半身、全身合一)的逼真人体视频,真实感源自动作、光照、纹理细节等综合方面。
官方项目链接:https://omnihuman-lab.github.io
![图片[2]-OmniHuman-1 多模态 “真人”视频生成项目! 效果真不错-零度博客](https://www.freedidi.com/wp-content/uploads/2025/03/51b19b232220250306200116.webp)
歌唱
OmniHuman 可以支持各种音乐风格,并适应多种身体姿势和歌唱形式。它可以处理高音调的歌曲,并针对不同类型的音乐显示不同的动作风格。请记住选择最高的视频质量。生成的视频质量也高度依赖于参考图像的质量。
与视频驾驶的兼容性
由于OmniHuman的混合条件训练特性,它不仅可以支持音频驾驶,还可以支持视频驾驶来模仿特定的视频动作,以及像最近的方法一样结合音频和视频驾驶来控制特定的身体部位。
道德问题
这些演示中使用的图像和音频来自公开来源或由模型生成,仅用于展示本研究工作的能力。如有任何问题,请联系我们(jianwen.alan@gmail.com),我们将及时删除。本网页模板基于VASA-1的模板,部分测试音频来自VASA-1、Loopy、CyberHost。
BibTeX
如果您发现这个项目对您的研究有用,您可以引用我们并查看我们的其他相关作品:
@article{lin2025omnihuman1,
title={OmniHuman-1: Rethinking the Scaling-Up of One-Stage Conditioned Human Animation Models},
author={Gaojie Lin and Jianwen Jiang and Jiaqi Yang and Zerong Zheng and Chao Liang},
journal={arXiv preprint arXiv:2502.01061},
year={2025}
}
@article{jiang2024loopy,
title={Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency},
author={Jiang, Jianwen and Liang, Chao and Yang, Jiaqi and Lin, Gaojie and Zhong, Tianyun and Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.02634},
year={2024}
}
@article{lin2024cyberhost,
title={CyberHost: Taming Audio-driven Avatar Diffusion Model with Region Codebook Attention},
author={Lin, Gaojie and Jiang, Jianwen and Liang, Chao and Zhong, Tianyun and Yang, Jiaqi and Zheng, Yanbo},
journal={arXiv preprint arXiv:2409.01876},
year={2024}
}
THE END