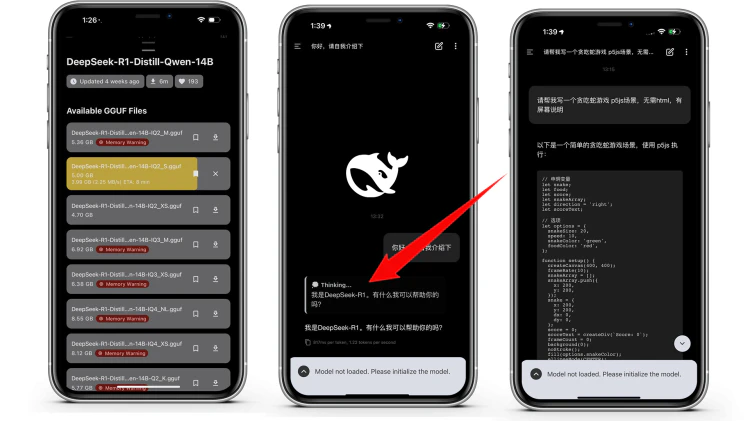
就在马斯克发布Grok 3大模型后当天,DeepSeek 就重磅推出 NSA 功能!这是长文本建模的突破性进展,在处理长序列文本起到非常关键的作用,处理长文本、编写长篇故事更强!消息发布后就迎来大量的围观。

近年来,语言模型被要求处理越来越长的上下文。这种需求暴露了标准注意力机制中的一些固有问题。全注意力的二次复杂度在处理长序列时很快成为瓶颈。内存使用量和计算需求迅速增加,使得多轮对话或复杂推理任务等实际应用面临挑战。此外,虽然稀疏注意力方法有望带来理论上的改进,但它们往往难以将这些好处转化为现实世界的加速。
许多挑战源于理论效率与实际实施之间的脱节。在不丢失重要信息的情况下减少计算开销并非易事。这促使研究人员重新思考注意力机制,以便更好地平衡性能和效率。解决这些问题是构建可扩展且有效的模型的关键一步。
DeepSeek AI 研究人员推出了 NSA,这是一种与硬件一致且可本地训练的稀疏注意力机制,用于超快速长上下文训练和推理。NSA 集成了算法创新和与硬件一致的优化,以降低处理长序列的计算成本。NSA 使用动态分层方法。它首先将标记组压缩为汇总表示。然后,它通过计算重要性分数有选择地仅保留最相关的标记。此外,滑动窗口分支可确保保留本地上下文。这种三管齐下的策略(压缩、选择和滑动窗口)创建了一种浓缩表示,同时仍可捕获全局和本地依赖关系。
NSA 的设计也考虑到了硬件限制。通过实施针对现代 GPU 优化的专用内核,NSA 实现了推理和训练的延迟降低。这种算法策略和硬件协调的精心融合使 NSA 成为改进长上下文建模的有希望的候选方案。
![图片[2]-DeepSeek 重磅推出 NSA 功能!处理长文本、编写长篇故事更强-零度博客](https://www.freedidi.com/wp-content/uploads/2025/02/003148-.webp "Screenshot 2025-02-18 at 7.55.03 PM")
技术细节和优势
NSA 的架构基于两个主要支柱:硬件感知设计和易于训练的算法。压缩机制使用可学习的多层感知器将顺序标记聚合为块级表示。这可以捕获高级模式,同时减少对全分辨率处理的需求。
压缩后,标记选择模块以块方式运行。它选择具有相似注意力分数的连续标记块,这有助于最大限度地减少随机内存访问。滑动窗口组件负责处理本地上下文。通过分离本地和全局信息,NSA 设法保留了许多任务所必需的细节。在硬件方面,NSA 优化了 GPU 资源的使用。查询以组为单位加载到 SRAM 中,并通过有效共享内存来最大限度地减少冗余键值传输。这些优化可显著提高前向和后向计算的速度。实验结果表明,对于长序列,前向传播速度提高了 9 倍,后向传播速度提高了 6 倍。
NSA 的核心组件:
- 动态分层稀疏策略
- 粗粒度标记压缩
- 细粒度的 token 选择
![图片[3]-DeepSeek 重磅推出 NSA 功能!处理长文本、编写长篇故事更强-零度博客](https://www.freedidi.com/wp-content/uploads/2025/02/003149-.webp "Screenshot 2025-02-18 at 7.55.22 PM")
结果和见解
该研究对 NSA 在各种任务中的性能进行了仔细评估。在 MMLU、GSM8K 和 DROP 等基准测试中,NSA 的性能可与传统的全注意力模型相媲美,甚至更好。该设计在长上下文场景中也证明是有效的,在这些场景中,保持全局意识和局部精度至关重要。
一个有趣的观察结果是,NSA 在长达 64k 个标记的序列的“大海捞针”任务中具有很高的检索准确率。这在很大程度上归功于其分层设计,该设计将粗略的全局扫描与详细的局部选择相结合。结果还表明,由于 NSA 的内存访问占用空间减少,其解码速度可以随着序列长度的增加而很好地扩展。这些见解表明,NSA 的平衡方法(结合压缩、选择和滑动窗口处理)提供了一种在不牺牲准确性的情况下有效处理长序列的实用方法。
![图片[4]-DeepSeek 重磅推出 NSA 功能!处理长文本、编写长篇故事更强-零度博客](https://www.freedidi.com/wp-content/uploads/2025/02/003150-.webp "Screenshot 2025-02-18 at 7.55.52 PM")
结论
NSA 标志着稀疏注意力机制设计向前迈出了深思熟虑的一步。通过将可训练性与硬件优化相结合,NSA 解决了计算效率和有效的长上下文建模的双重挑战。它的三层方法包括标记压缩、选择性注意和滑动窗口处理,可在保留重要上下文的同时减少计算开销。