

DeepSeek-V3 是由国人工智能公司DeepSeek开发的最新开源大型语言模型(LLM),于2024年12月发布。
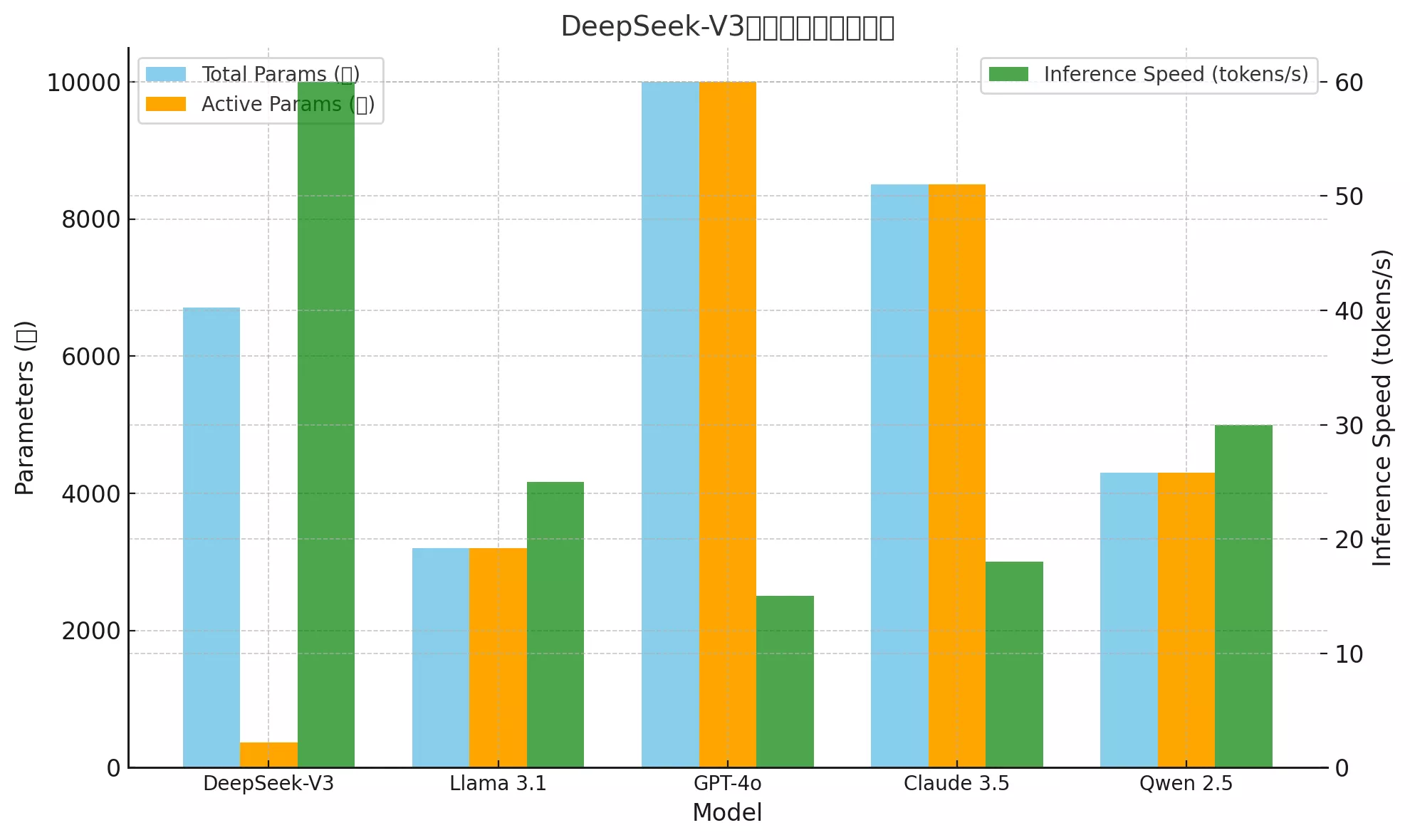
该模型采用了混合专家(Mixture-of-Experts,MoE)架构,拥有总计6710亿参数,每个token激活其中的370亿参数。
在性能方面,DeepSeek-V3在多项基准测试中表现出色,超越了Llama 3.1和Qwen 2.5等模型,并与GPT-4o和Claude 3.5 Sonnet等先进的闭源模型相媲美。
以下是DeepSeek-V3与一些同类模型(如Llama 3.1、GPT-4、Claude 3.5 Sonnet、Qwen 2.5等)的参数对比表:
| 模型名称 | 总参数量 | 激活参数量 | 架构 | 推理速度 | 训练成本 | 发布时间 |
|---|---|---|---|---|---|---|
| DeepSeek-V3 | 6710亿 | 370亿 | 混合专家(MoE) | 60 tokens/s | $5.58M | 2024年12月 |
| Llama 3.1 | 3200亿 | 3200亿 | Transformer | 25 tokens/s | 未公开 | 2024年11月 |
| GPT-4o | 1万亿 | 1万亿 | Transformer | 15 tokens/s | 超过$100M | 2024年6月 |
| Claude 3.5 | 8500亿 | 8500亿 | Transformer | 18 tokens/s | 未公开 | 2024年10月 |
| Qwen 2.5 | 4300亿 | 4300亿 | 基于Transformer改进 | 30 tokens/s | 未公开 | 2024年11月 |
详细说明
- 总参数量:表示模型的总参数规模,通常决定了模型的容量。
- 激活参数量:对于MoE架构,表示每次推理激活的参数量;而标准Transformer架构通常等于总参数量。
- 架构:DeepSeek-V3采用混合专家架构,能够高效激活部分专家参数,从而提升推理速度和能效。
- 推理速度:DeepSeek-V3的推理速度领先,适合实时应用场景。
- 训练成本:DeepSeek-V3显示了开源模型在成本控制上的优势,与闭源模型(如GPT-4)形成鲜明对比。
- 发布时间:DeepSeek-V3是目前最新的开源模型之一,适应了最新的研究进展和需求。
![图片[1]-DeepSeek-V3 的Q4_k_m 量化版本下载!-零度博客](https://www.freedidi.com/wp-content/uploads/2025/01/ebf84e74b220250105125928-800x477.webp)
此外,DeepSeek-V3在推理速度上也取得了显著突破,推理速度比之前的模型提高了3倍,达到每秒60个token。
值得注意的是,DeepSeek-V3的训练成本约为558万美元,耗时约55天,显示了在有限资源下的高效优化能力。
用户可以通过DeepSeek的官方网站免费体验DeepSeek-V3,或通过API进行集成。
此外,DeepSeek-V3的模型权重已在GitHub上开源,开发者可以下载并在本地进行部署。
总体而言,DeepSeek-V3作为开源模型,在性能和效率上均达到了当前的领先水平,为人工智能领域的研究和应用提供了强大的工具。
而且现在已经放出了 DeepSeek-V3 的Q4_k_m 量化版本了,大小比原本的小一半。
DeepSeek-V3 的Q4_k_m 量化版本:【点击下载】
![图片[2]-DeepSeek-V3 的Q4_k_m 量化版本下载!-零度博客](https://www.freedidi.com/wp-content/uploads/2025/01/1421dbf89420250105130043-800x364.webp)
THE END