Open Chat Video Editor
一款短视频生成和编辑工具,结合 ChatGPT,Stable Diffusion 和多模态搜索,实现短句转短视频、网页链接转短视频、长视频转短视频功能。
下载方式:
1、Github 开源项目【点击前往】
2、备用打包下载 【点击下载】
结果展示
1、短句转短视频(Text2Video)
界面如下: 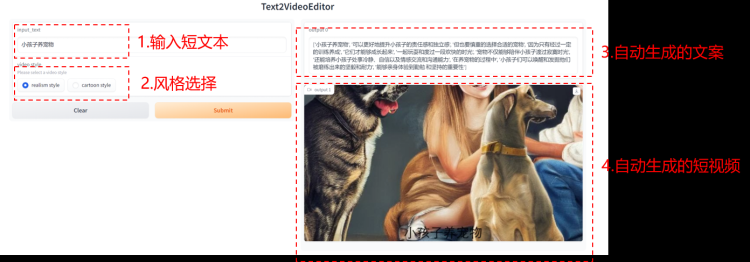 以输入文案:【小孩子养宠物】为例,利用文本模型(如:chatgpt 等),可以自动生成一个较长的短视频文案:
以输入文案:【小孩子养宠物】为例,利用文本模型(如:chatgpt 等),可以自动生成一个较长的短视频文案:
['小孩子养宠物', '可以更好地提升小孩子的责任感和独立感', '但也要慎重的选择合适的宠物', '因为只有经过一定的训练养成', '它们才能够成长起来', '一起玩耍和度过一段欢快的时光', '宠物不仅能够陪伴小孩子渡过寂寞时光', '还能培养小孩子处事冷静、自信以及情感交流和沟通能力', '在养宠物的过程中', '小孩子们可以唤醒和发掘他们被磨练出来的坚毅和耐力', '能够亲身体验到勤勉 和坚持的重要性']
![图片[2]-Open Chat Video Editor 一款短视频生成和编辑工具-零度博客](https://www.freedidi.com/wp-content/uploads/2024/09/20240909143023.webp)
根据不同的视频生成模式,可以生成不同的视频,各个模式对比如下:
1)图像检索
default.mp4
2)图像生成(stable diffusion)
default.mp4
3)先图像检索,再基于stable diffusion 进行图像生成
+.mp4
4)视频检索
default.mp4
2、网页转短视频(Url2Video)
界面如下:
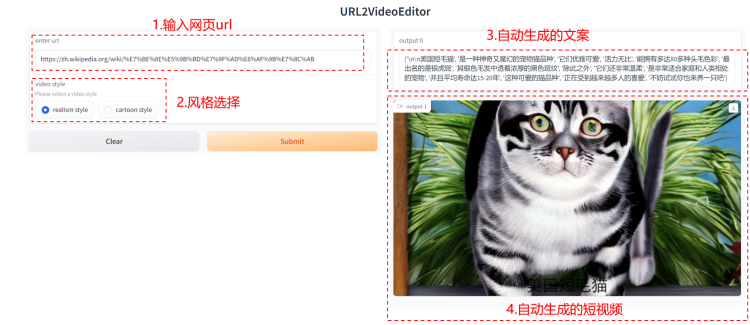
1)输入一个url, 例如:https://zh.wikipedia.org/wiki/%E7%BE%8E%E5%9B%BD%E7%9F%AD%E6%AF%9B%E7%8C%AB 其内容是:美国短毛猫的维基百科
2)解析网页并自动摘要成短视频文案,结果如下:
['\n\n美国短毛猫', '是一种神奇又魔幻的宠物猫品种', '它们优雅可爱', '活力无比', '能拥有多达80多种头毛色彩', '最出名的是银虎斑', '其银色毛发中透着浓厚的黑色斑
纹', '除此之外', '它们还非常温柔', '是非常适合家庭和人类相处的宠物', '并且平均寿命达15-20年', '这种可爱的猫
品种', '正在受到越来越多人的喜爱', '不妨试试你也来养一只吧']
3)自动合成短视频 例如图像生成模式下生成的结果如下,其他模式不再一一对比
url.mp4
3、长视频转短视频(Long Video to Short Video)
即将发布,敬请期待
安装与使用
环境安装
首先下载源码
git clone https://github.com/SCUTlihaoyu/open-chat-video-editor.git
根据不同需求,选择不同的安装方式1、2、和3、任选其一。
1、Docker
目前docker环境因为每个人的cuda版本可能不一样,所以无法保证都能够正常使用GPU。目前支持图像检索模式,CPU机器也可以使用。但docker比较大,需要占用比较多的储存(24G)。 YourPath表示存放上面下载的代码的路径
docker pull iamjunhonghuang/open-chat-video-editor:retrival
docker run -it --network=host -v /YourPath/open-chat-video-editor:/YourPath/open-chat-video-editor/ iamjunhonghuang/open-chat-video-editor:retrival bash
conda activate open_editor
或者使用阿里云的镜像:
docker login --username=xxx registry.cn-hangzhou.aliyuncs.com
docker pull registry.cn-hangzhou.aliyuncs.com/iamjunhonghuang/open-chat-video-editor:retrival
docker run -it --network=host -v /YourPath/open-chat-video-editor:/YourPath/open-chat-video-editor/ registry.cn-hangzhou.aliyuncs.com/iamjunhonghuang/open-chat-video-editor:retrival bash
conda activate open_editor
注意:目前暂不支持中文字幕显示,所以需要修改配置文件yaml中的字体设置,例如’image_by_retrieval_text_by_chatgpt_zh.yaml‘
subtitle:
font: DejaVu-Sans-Bold-Oblique
# font: Cantarell-Regular
# font: 华文细黑
2、Linux (目前仅在centOS测试)
1)首先安装基于conda的python环境,gcc版本安装测试时是8.5.0,所以尽量升级到8以上
conda env create -f env.yaml
conda env update -f env.yaml #假如第一行出现错误,需要更新使用的命令
2) 接着安装环境依赖,主要目的是正常安装ImageMagick,其他linux版本可以参考
# yum groupinstall 'Development Tools'
# yum install ghostscript
# yum -y install bzip2-devel freetype-devel libjpeg-devel libpng-devel libtiff-devel giflib-devel zlib-devel ghostscript-devel djvulibre-devel libwmf-devel jasper-devel libtool-ltdl-devel libX11-devel libXext-devel libXt-devel libxml2-devel librsvg2-devel OpenEXR-devel php-devel
# wget https://www.imagemagick.org/download/ImageMagick.tar.gz
# tar xvzf ImageMagick.tar.gz
# cd ImageMagick*
# ./configure
# make
# make install
3)需要修改moviepy的调用路径,也就是将下面文件
$HOME/anaconda3/envs/open_editor/lib/python3.8/site-packages/moviepy/config_defaults.py
修改成
#IMAGEMAGICK_BINARY = os.getenv('IMAGEMAGICK_BINARY', 'auto-detect')
IMAGEMAGICK_BINARY='/usr/local/bin/magick'
4)目前暂不支持中文字幕显示,所以需要修改配置文件yaml中的字体设置,例如’image_by_retrieval_text_by_chatgpt_zh.yaml‘
subtitle:
font: DejaVu-Sans-Bold-Oblique
# font: Cantarell-Regular
# font: 华文细黑
3、Windows
1)建议使用python 3.8.16版本:
conda create -n open_editor python=3.8.16
2)安装pytorch
# GPU 版本
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117
# CPU版本
pip3 install torch torchvision torchaudio
3)安装其他依赖环境
pip install -r requirements.txt
4)安装clip
pip install git+https://github.com/openai/CLIP.git
5)安装faiss
conda install -c pytorch faiss-cpu
代码执行
1)根据实际需要,选择不同的配置文件
| 配置文件 | 说明 |
|---|---|
| configs/text2video/image_by_retrieval_text_by_chatgpt_zh.yaml | 短文本转视频,视频文案采用chatgpt生成,视觉部分采用图像检索来生成 |
| configs\text2video\image_by_diffusion_text_by_chatgpt_zh.yaml | 短文本转视频,视频文案采用chatgpt生成, 视觉部分采用图像stable diffusion 来生成 |
| configs\text2video\image_by_retrieval_then_diffusion_chatgpt_zh.yaml | 短文本转视频,视频文案采用chatgpt生成,视觉部分采用先图像检索,然后再基于图像的stable diffusion 来生成 |
| configs\text2video\video_by_retrieval_text_by_chatgpt_zh.yaml | 短文本转视频, 视频文案采用chatgpt生成,视觉部分采用视频检索来生成 |
| configs\url2video\image_by_retrieval_text_by_chatgpt.yaml | url转视频,视频文案采用chatgpt生成,视觉部分采用图像检索来生成 |
| configs\url2video\image_by_diffusion_text_by_chatgpt.yaml | url转视频,视频文案采用chatgpt生成, 视觉部分采用图像stable diffusion 来生成 |
| configs\url2video\image_by_retrieval_then_diffusion_chatgpt.yaml | url转视频,视频文案采用chatgpt生成,视觉部分采用先图像检索,然后再基于图像的stable diffusion 来生成 |
| configs\url2video\video_by_retrieval_text_by_chatgpt.yaml | url转视频,视频文案采用chatgpt生成,视觉部分采用视频检索来生成 |
需要注意的是:如果要采用ChatGPT来生成文案,需要在配置文件里面,添加organization_id(要在Organization settings那里查,而不是直接输入“personal”)和 api_key
2)下载数据索引和meta信息data.tar,并解压到 data/index 目录下,
3)执行脚本。注意:下面的${cfg_file}指的是是上面列表中的配置文件的路径,不同配置文件会运行不同的模式。例如:将下面${cfg_file}更改成configs/text2video/image_by_retrieval_text_by_chatgpt_zh.yaml
# Text to video
python app/app.py --func Text2VideoEditor --cfg ${cfg_file}
# URL to video
python app/app.py --func URL2VideoEditor --cfg ${cfg_file}