![图片[1]-微软推出最新视觉基础模型Florence-2 ,可在WebGPU的浏览器独立运行!-零度博客](https://www.freedidi.com/wp-content/uploads/2024/07/fine-tune-florence-2.webp)
Florence-2:微软全新开源视觉模型!
能够执行超过10种不同的视觉任务 包括图像字幕生成、对象检测、图像区域关联和分割等。
它不仅能描述图片的内容,还能识别图片中的物体,并指出这些物体的位置。
比如,如果你给它一张公园里的图片,它可以告诉你图片里有一个穿蓝衣服的女孩在玩耍,旁边还有一只狗。
Florence-2 系列包括 Florence-2-base 和 Florence-2-large,参数分别为 0.23 亿和 0.77 亿。尽管模型较小,但性能并不逊色。
可以运行在各种资源受限的移动端设备上。 Florence-2 采用统一的、基于提示的表示方式来处理各种视觉任务。 通过简单的文本提示,模型可以生成所需的文本形式结果,无论是图片描述、目标检测、视觉定位还是图像分割。这种方法简化了多任务处理的复杂性,提高了模型的通用性和适应性
![图片[2]-微软推出最新视觉基础模型Florence-2 ,可在WebGPU的浏览器独立运行!-零度博客](https://www.freedidi.com/wp-content/uploads/2024/07/Florence-2.webp)
Florence-2是Microsoft 在MIT 许可下开源的轻量级视觉语言模式。该模型在字幕、物件侦测、接地和分割等任务中展示了强大的零样本和微调功能。
尽管尺寸很小,但它所取得的结果与大许多倍的模型(如Kosmos-2)相当。该模型的优势不在于复杂的架构,而在于大规模的FLD-5B 资料集,其中包含1.26 亿张影像和54 亿个综合视觉注释。
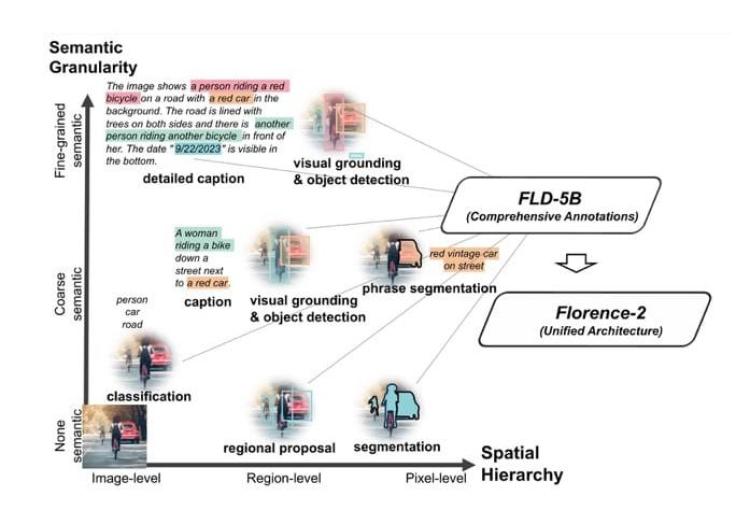
该模型支持多种功能,可用于生成图像、识别字元、分割图像、检测物体等等。
Florence-2 比其前身更小、更精确。 Florence-2系列由两个模型组成:Florence-2-base和Florence-2-large,分别有2.3亿和7.7亿参数。此尺寸甚至允许部署在行动装置上。
尽管规模较小,但Florence-2 在所有基准测试中都取得了比Kosmos-2 更好的零样本结果,尽管Kosmos-2 拥有16 亿个参数。
Florence-2的本地化运行得益于Transformers.js和ONNX Runtime Web技术的支持。这一突破不仅提高了使用者隐私保护水平,还大大降低了使用成本,为AI视觉技术的普及应用铺平了道路。












 会员专属
会员专属