

![图片[1]-ChatTTS 本地部署教程!目前最好用的文字转语音工具!-零度博客](https://www.freedidi.com/wp-content/uploads/2024/06/1-1.webp)
1.安装Python 和 git环境,python需要 3.9+ 版本,比如我选择python 3.10.6 【点击下载】
然后安装下git环境:【官方下载】
2.下载 chatTTS-ui 【点击下载】
3.解压后在根目录下输入CMD进入终端,然后依次执行下面的安装命令:
python -m venv venv .\venv\scripts\activate pip install -r requirements.txt
4.如果不需要CUDA加速,执行
pip install torch==2.1.2 torchaudio==2.1.2
如果需要CUDA加速,执行
pip install torch==2.1.2 torchaudio==2.1.2 --index-url https://download.pytorch.org/whl/cu118
如果你没有安装CUDA+ ToolKit, 可以看下这篇文章:【点击查看】
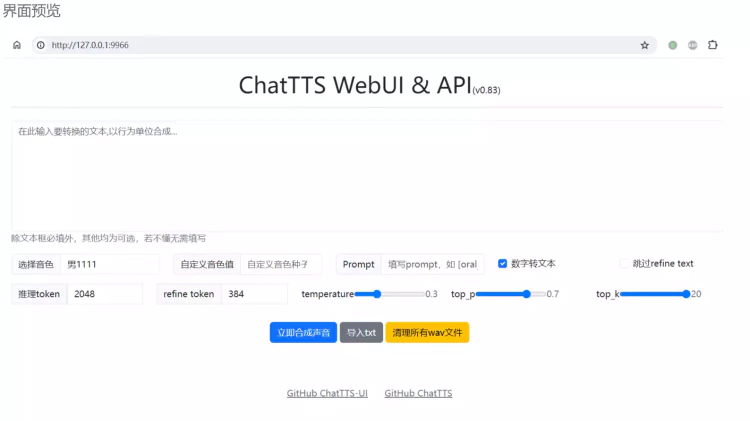
5.最后执行 python app.py 启动,将自动打开浏览器窗口,默认地址 http://127.0.0.1:9966
(注意:默认从 modelscope 魔塔下载模型,不可使用代理下载,请关闭代理)
6.源码部署启动后,会先从 modelscope下载模型,但modelscope缺少spk_stat.pt,会报错,【点击下载 spk_stat.pt】
下载后将该文件复制到 项目目录/models/pzc163/chatTTS/asset/ 文件夹内
注意 modelscope 仅允许中国大陆ip下载模型,如果遇到 proxy 类错误,请关闭代理。
如果你希望从 huggingface.co 下载模型,请打开 app.py 查看大约第50行-60行的注释。如果需要GPU加速,必须是英伟达显卡,并且安装 cuda版本的torch
# 默认从 modelscope 下载模型,如果想从huggingface下载模型,请将以下3行注释掉
CHATTTS_DIR = snapshot_download('pzc163/chatTTS',cache_dir=MODEL_DIR)
chat = ChatTTS.Chat()
chat.load_models(source="local",local_path=CHATTTS_DIR)
# 如果希望从 huggingface.co下载模型,将以下注释删掉。将上方3行内容注释掉
#os.environ['HF_HUB_CACHE']=MODEL_DIR
#os.environ['HF_ASSETS_CACHE']=MODEL_DIR
#chat = ChatTTS.Chat()
#chat.load_models()
THE END